我最近发现一个极其有价值的资源——“AI大模型硬件架构”,这个资料包通常要付费169元,现在可以通过网盘免费下载,内容毫无加密限制。
知识体系亮点
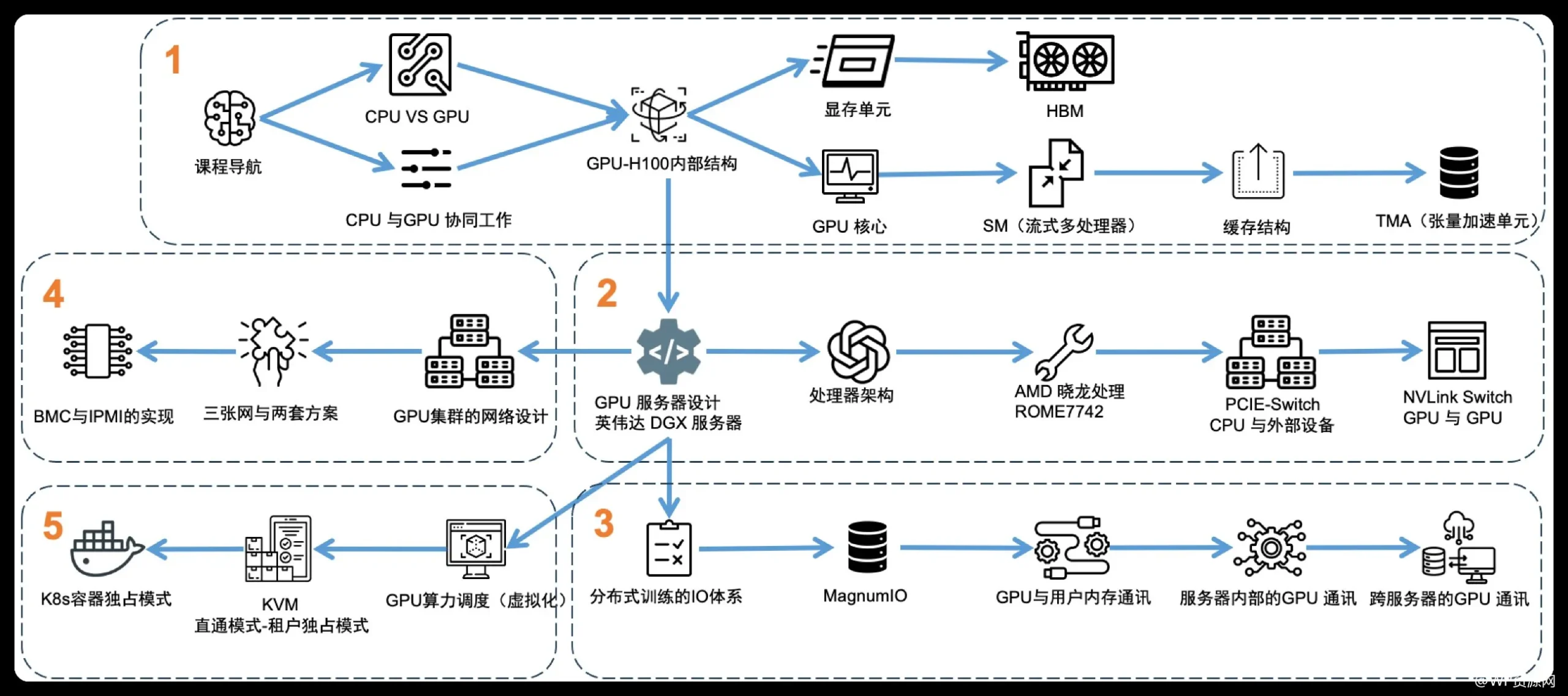
该资料包详细解析了当前流行的AI大模型在硬件层面上的最佳实践和优化策略。从GPU到TPU的各种加速器,再到高性能网络架构的设计理念,一应俱全。特别值得一提的是,它涵盖了最新的研究进展和技术趋势。
学习建议
如果你是AI领域深度爱好者或行业从业者,这样的资料包简直就是宝藏级别的资源。我强烈推荐先从基础理论部分开始入手,然后再逐步深化到具体架构设计与优化方法论的学习上。这不仅有助于理解现有系统的工作原理,还能激发你在未来创新中寻找新方向的灵感。
最后提醒:这样的宝贵信息非常稀缺,值得所有对AI硬件感兴趣的同学去下载和学习。但请确保自己的网盘空间足够大哦!
资源来源:点击访问原网址
版权声明:资源仅供研究,请支持正版。
版权声明:资源仅供研究,请支持正版。
资源下载
下载价格19 金币
VIP免费升级VIP
点击检测网盘有效后购买



评论0